#
Model re-training
To improve the effectiveness of the trained model, you can subject it to a re-training process. To start, go to the Models section, hover over the gear icon and click the Re-train button on the selected model tile.
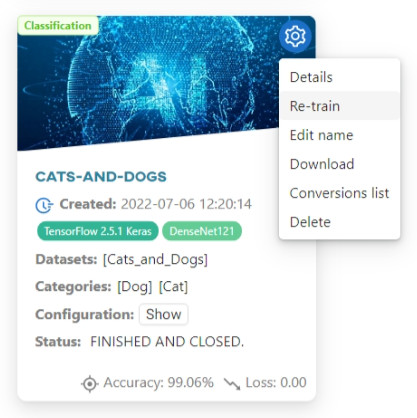
Retraining process consists of three steps:
- Editing the dataset;
- Merging object classes;
- Configuring the model.
#
Editing datasets
In the first step, select the datasets you want to use for the re-training process.
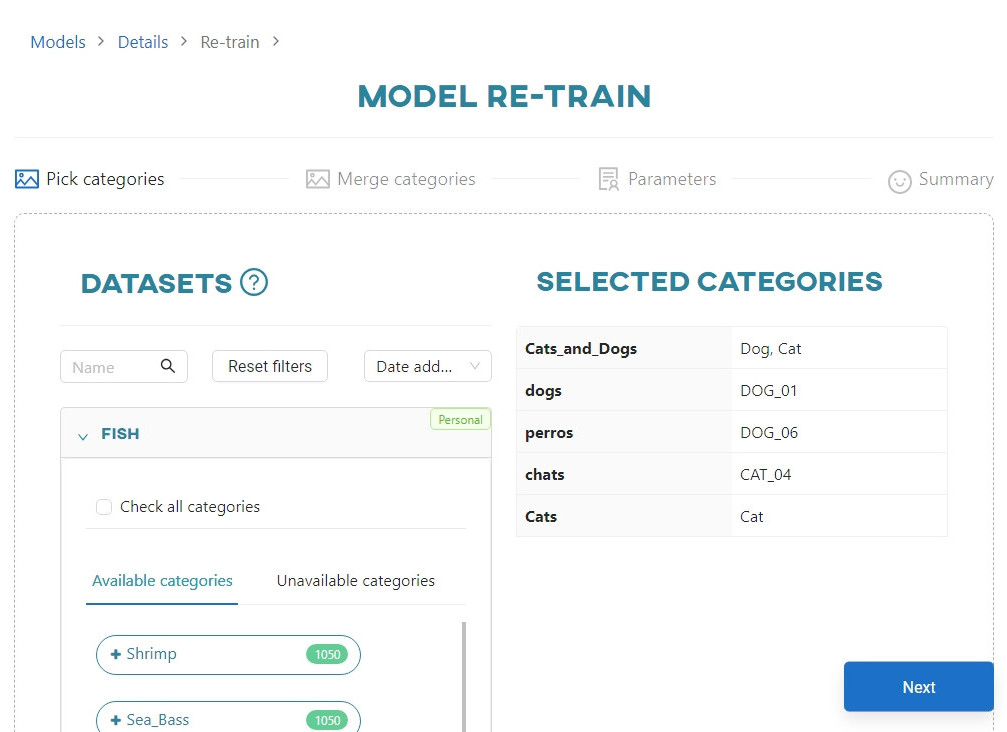
By default, the datasets that were used in the previous (original) training session are selected. You can deselect them if you want to use only the new datasets.
#
Merging object classes
Clicking the Next button takes you to the category merge view. It is slightly different from the original merge view:
- Categories from the previous training are automatically assigned to buckets
- If you have selected new categories, they will be assigned to the automatically generated
Unassignedbucket - If the name of a new category matches the name of an existing bucket, it will be automatically assigned to that bucket
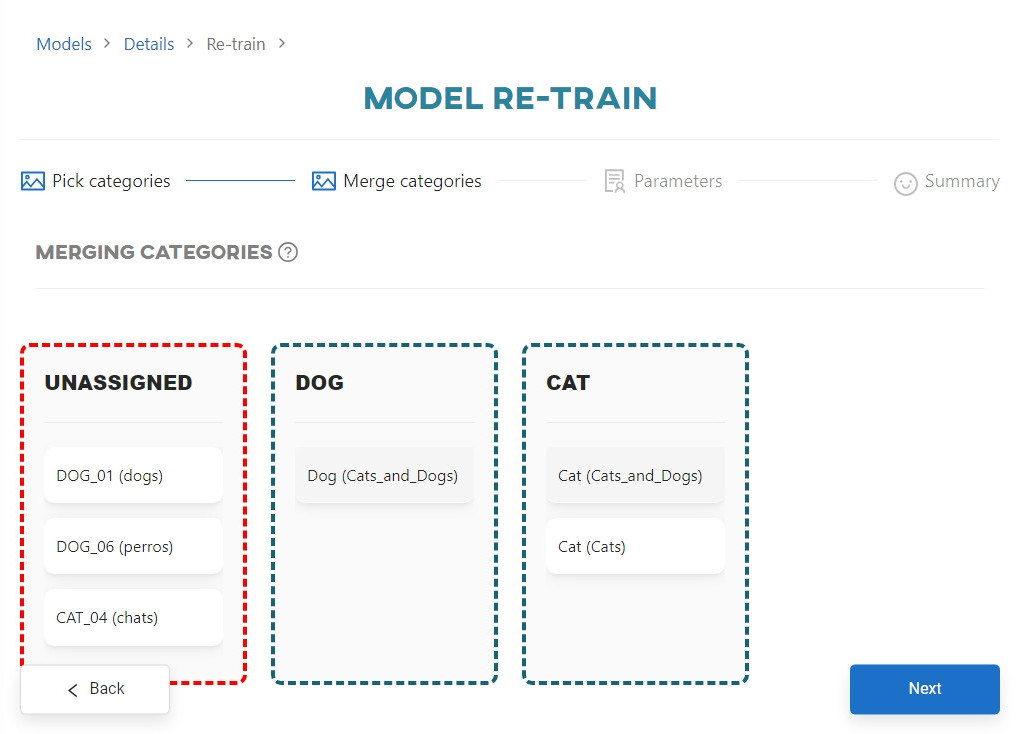
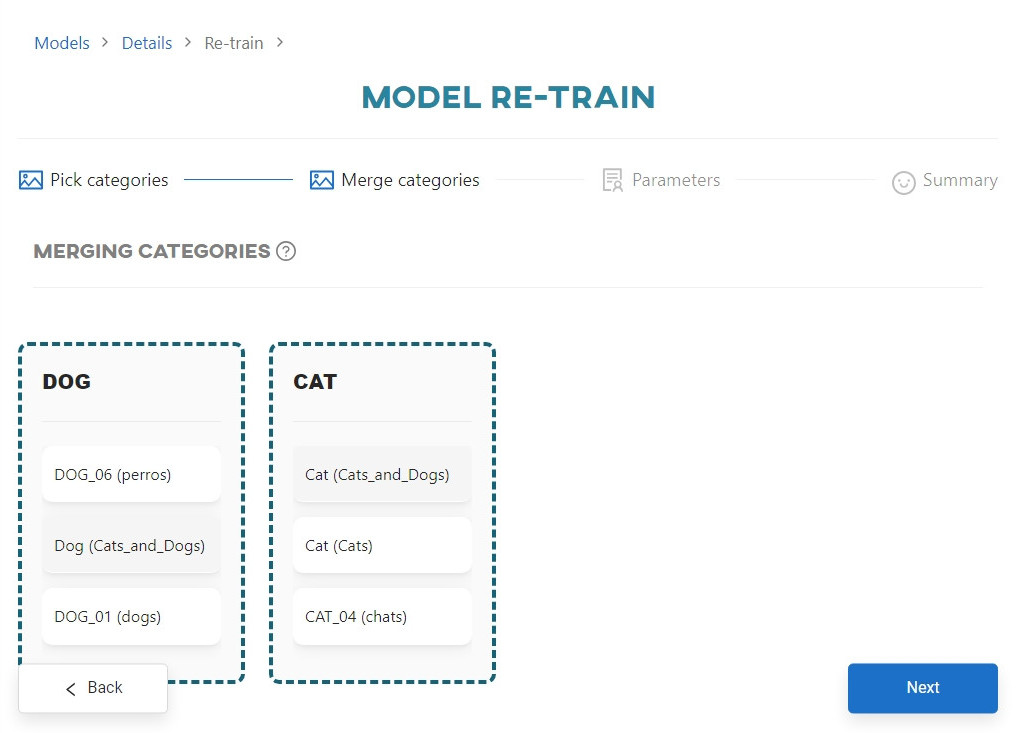
To start re-training, you need to move all dataset categories from the Unassigned bucket into the appropriate buckets. Only then will the Unassigned bucket be automatically deleted and the Re-train button be enabled. Each bucket must always contain at least one dataset category.
#
Model configuration
Click Next to proceed to the configuring the model step. Define the name of the re-trained model and the number of epochs (for classification) or iterations (for object detection).
The model name must meet the same validation requirements as for regular training.
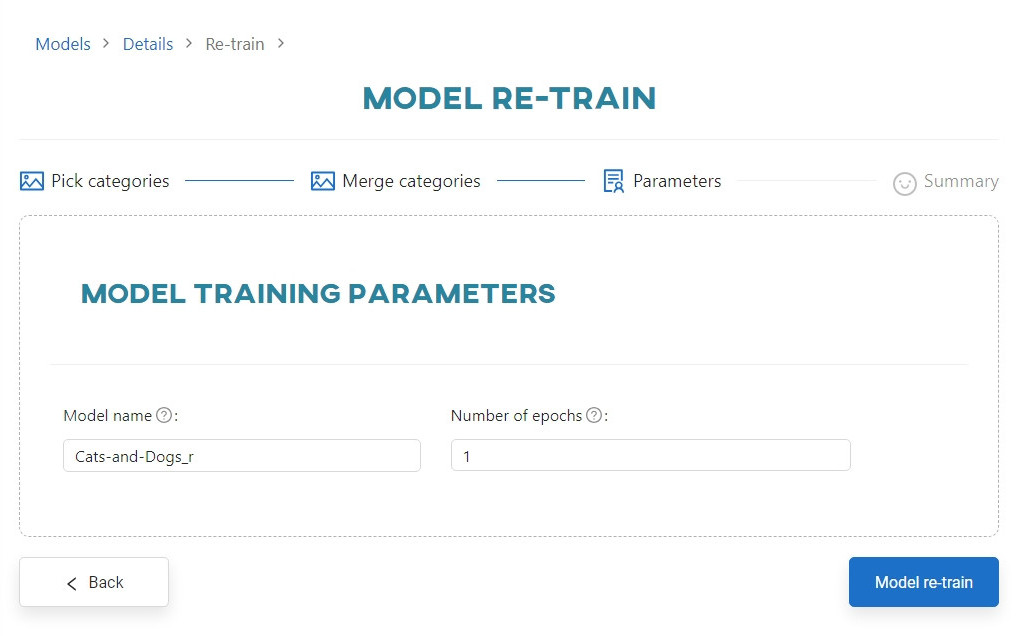
Click Re-train to start re-training the model.