#
Creating a model
Start creating a model by clicking the Add new model button in the model list view.
For a visual guide, check out the tutorial on our Youtube channel:
Creating a model consists of the following steps:
- Select training type
- Pick categories
- Merge categories
- Parametrization (varies depending on the selected framework)
- Start training
#
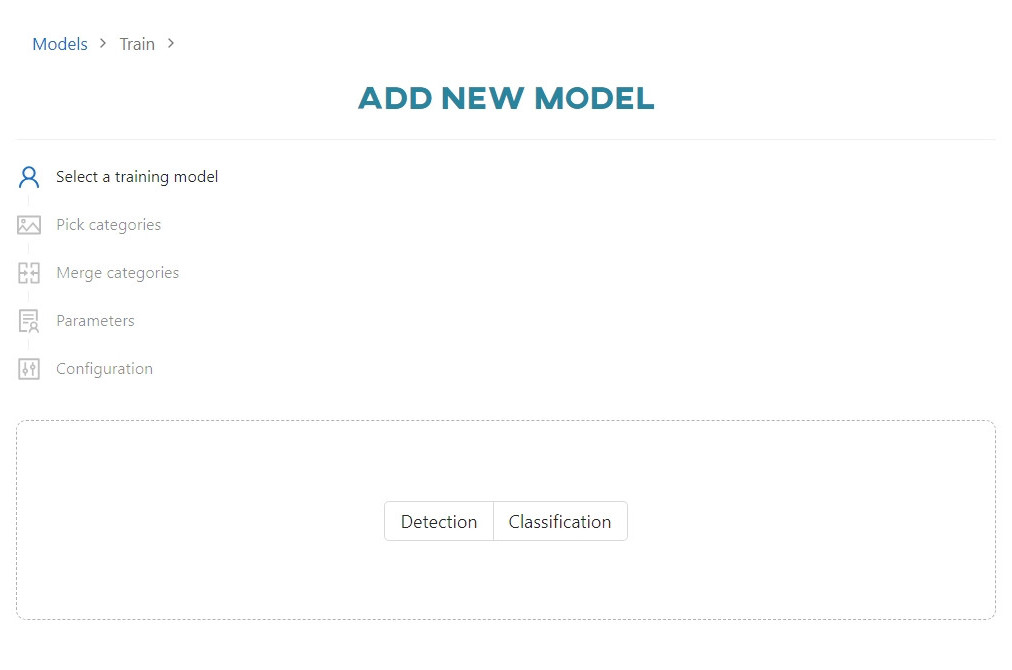
Select training type
First, select the type of model - Detection or Classification. Once chosen, you will be taken to the next step.
#
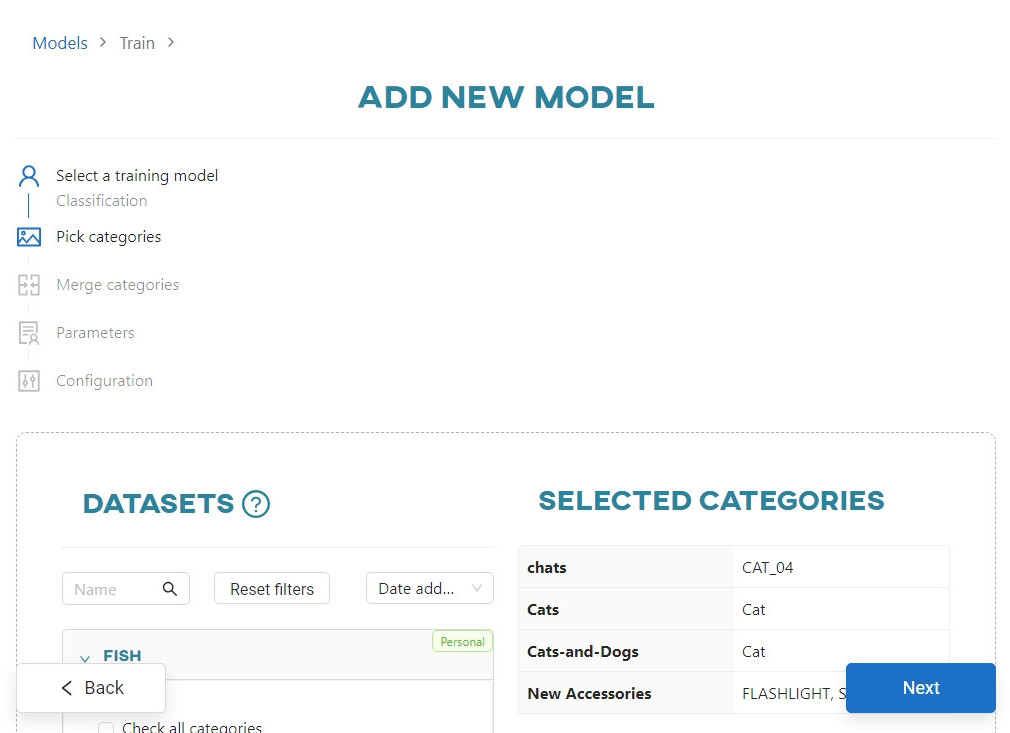
Pick categories
In this step, select the categories you want to use to train the neural network model. The categories are listed under the name of each available dataset. Each category must contain at least 3 images for the network to operate on it.
Keep in mind: In the Unsplash datasets, you can use up to 200 images per category for a training.
#
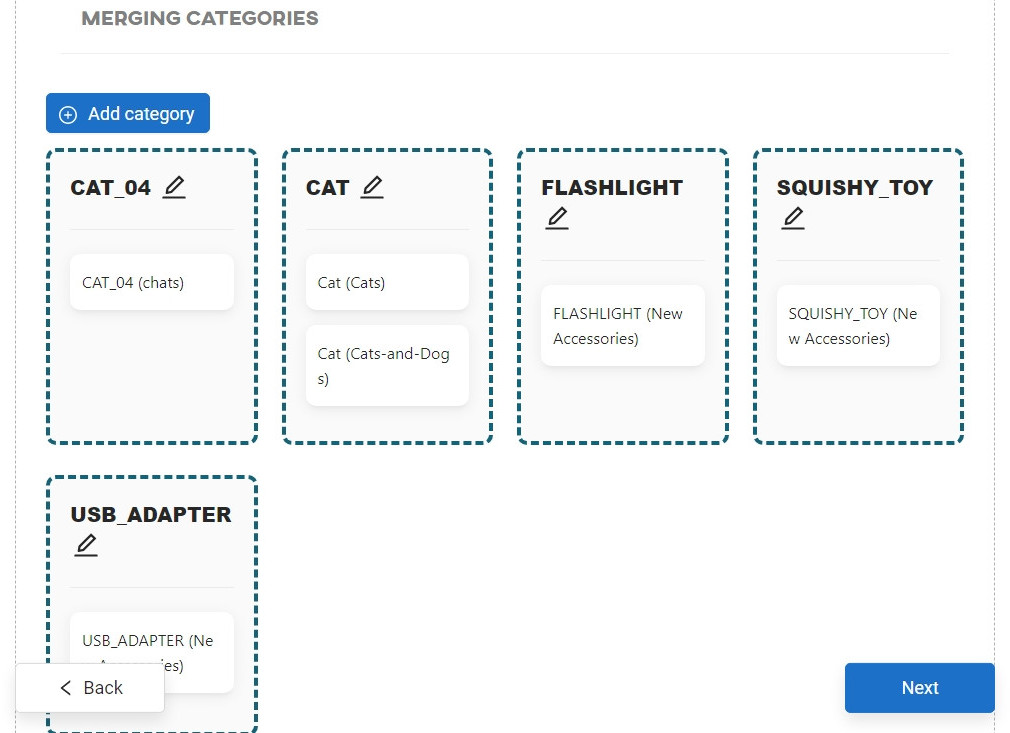
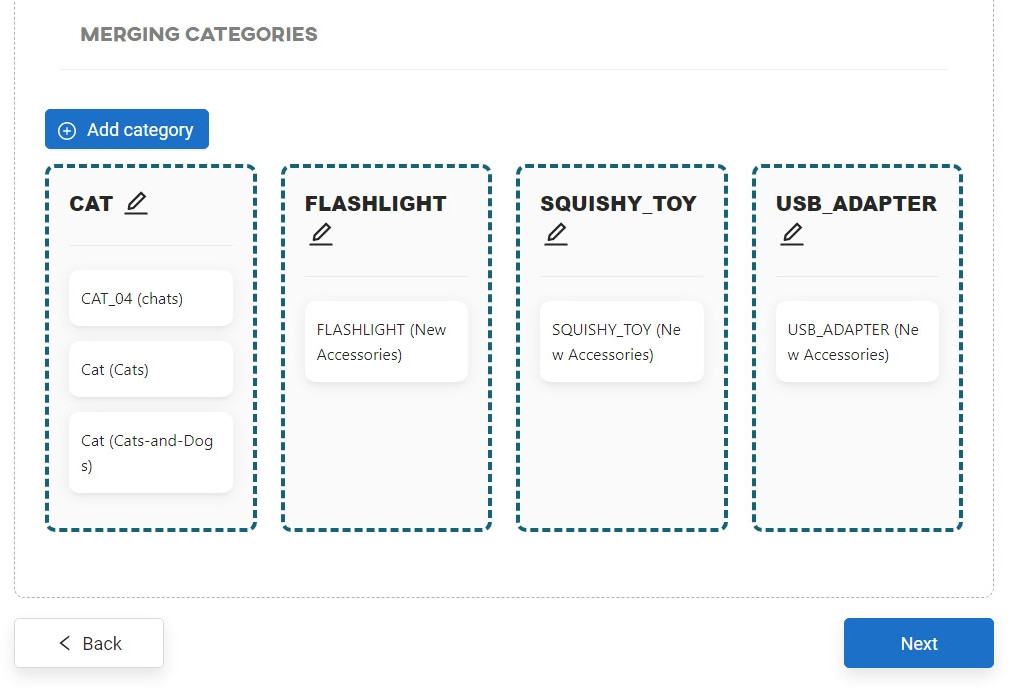
Merge categories
The categories selected in the previous step can be combined with each other. The whole process is described in more detail in the Merging datasets categories article.
#
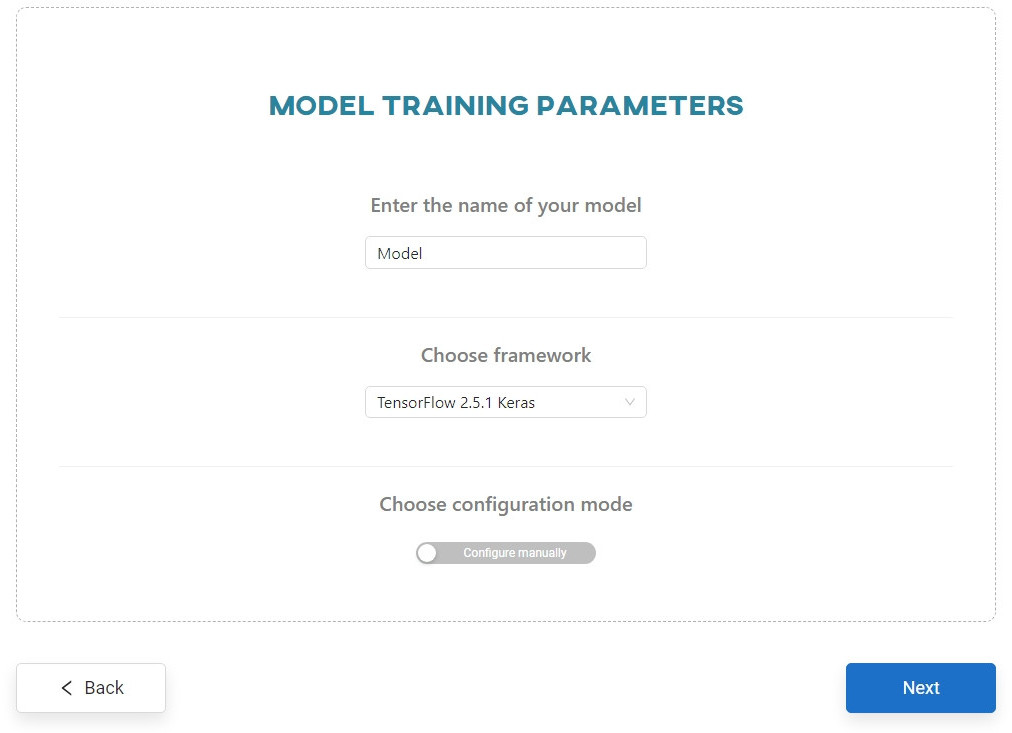
Pick parametrization way
Enter the model name (maximum of 50 characters; only Latin letters, numbers and hyphens are allowed) and select the framework to be used for training from the list of available frameworks.
There are two types of parametrization to choose from:
Manual Parametrization Automatic Parametrization
#
Manual Parametrization
#
Basic options
The basic configuration of the model consists of:
- Template (optional),
- Pretrained model.
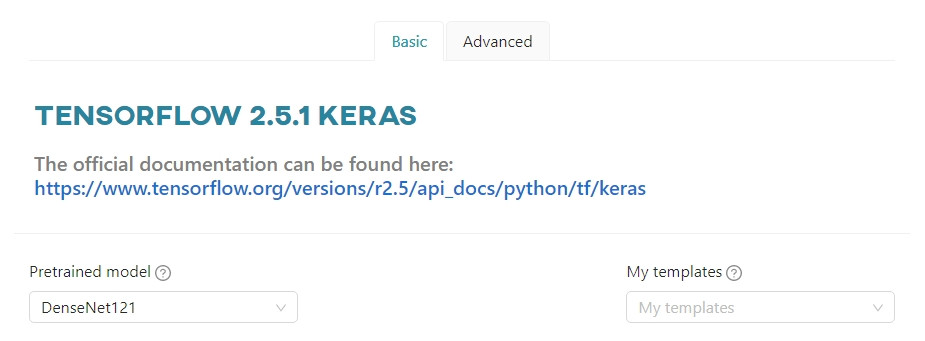
If you select Pretrained model, all parameter fields will be populated with default values that are the most optimal for the given pretrained model. It is possible to change these values, but radically changing the default parameters may reduce the performance of the trained model.
Here's a brief explanation of each pretrained model:
Darknet
YOLOv4.conv.137 - A variant of the YOLO (You Only Look Once) object detection model with 137 convolutional layers. It is known for its speed and accuracy.
YOLOv4-tiny.conv - A smaller and faster version of YOLOv4 for real-time object detection with reduced computational requirements.
Tensorflow 2.11
SSDMobileNetV2 - A combination of two popular architectures, SSD (Single Shot MultiBox Detector) and MobileNetV2. It offers a balance between speed and accuracy.
SSDMobileNetV1FPN - Like SSDMobileNetV2, this model combines SSD with the MobileNetV1 backbone, but also includes a Feature Pyramid Network (FPN). FPN enhances the model's ability to detect objects at different scales, improving accuracy.
EfficientDetD0 and EfficientDetD1 - Variants of the EfficientDet model, which is designed for efficient object detection. The D0 and D1 versions represent different model sizes and computational tradeoffs. D0 is more lightweight and faster, while D1 offers slightly higher accuracy at the cost of greater complexity.
CenterNetResnet50V1FPN and CenterNetResnet50V2 - CenterNet is an object detection model that focuses on detecting the center point of objects in images. These specific versions use the ResNet50 architecture with either a V1 or V2 variant and incorporate a Feature Pyramid Network (FPN) for better object detection and localization.
TensorFlow 2.5.1 Keras
DenseNet121, DenseNet169, DenseNet201, DenseNet161 - These are variations of the DenseNet architecture, known for its dense connectivity between layers. They are effective for image classification tasks, with the number indicating the depth and complexity of the model.
InceptionResNetV2 and InceptionV3 - These models combine features of Google's Inception and ResNet architectures. They are used for image classification and feature extraction tasks, with InceptionResNetV2 being a more advanced and deeper version.
MobileNet and MobileNetV2 - These are lightweight convolutional neural network architectures designed for mobile and embedded devices. MobileNetV2 is an enhanced version of the original MobileNet.
NASNetLarge and NASNetMobile - These models were developed through research in neural architecture. NASNetLarge is a large-scale network, while NASNetMobile is a smaller, mobile-friendly version. Both can be used for various computer vision tasks.
ResNet models (ResNet18, ResNet34, ResNet50, ResNet101, ResNet152) - These are members of the ResNet (Residual Network) family, with varying depths. They are known for their skip connections and are widely used for image classification and other vision tasks.
VGG16 and VGG19 - The VGG (Visual Geometry Group) models are known for their simplicity and deep architecture. VGG16 has 16 weighting layers, and VGG19 has 19 weighting layers. They are used for image classification and feature extraction.
Xception - A deep convolutional network architecture that emphasizes depthwise separable convolutions. It's designed for image classification and feature extraction tasks.
EfficientNetB0, B1, B2, B3, B4, B5 - These models are part of the EfficientNet family, which uses compound scaling to balance model size and performance. The number indicates different scaling factors and complexity levels, with B0 being the smallest and B5 being larger and more powerful.
Pytorch 1.8.1
SqueezeNet1.0 and SqueezeNet1.1 - SqueezeNet models are designed for efficient model inference and deployment. They achieve high accuracy at a reduced model size, making them suitable for resource-constrained devices. SqueezeNet1.1 is a slight improvement over SqueezeNet1.0.
GoogLeNet - Also known as the Inception architecture, GoogLeNet is known for its multiple inception modules that allow it to efficiently capture features at different scales. It is used for image classification and other vision tasks.
ShuffleNetV2_x1.0 and ShuffleNetV2_x0.5 - ShuffleNet is designed for efficient inference and memory usage. These models include channel shuffle operations, and x1.0 and x0.5 refer to different model scales. x0.5 is a lighter version.
MobileNetV3_large and MobileNetV3_small - These are variations of MobileNetV3, designed for mobile and edge devices. They provide a balance between accuracy and model size, with large being a more powerful version and small being a lighter version.
ResNeXt50_32x4d and ResNeXt101_32x8d - ResNeXt is a variant of ResNet that uses grouped convolutions. The numbers 32x4d and 32x8d refer to the number of groups and their width. A larger number indicates a more complex and powerful model.
WideResNet50_2 and WideResNet101_2 - WideResNet models are based on ResNet but with increased width. They provide improved performance by increasing the number of filters in each layer. The numbers 50_2 and 101_2 represent the depth and width of the models.
MnasNet1.0 and MnasNet0.5 - MnasNet models are designed for mobile devices. 1.0 and 0.5 indicate the model size, where 1.0 is the larger variant, while 0.5 is lighter.
If you want to keep the default values, you can go to the next step - Start training.
#
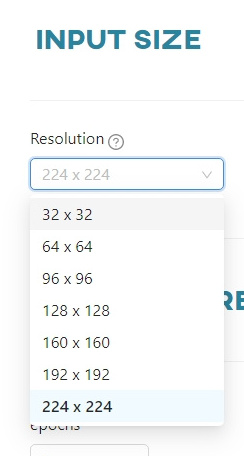
Input size
The input size represents the resolution of the images processed by the neural network. This is the resolution that the network expects as input. Images from datasets that will be used in the training process will also be scaled to this resolution. For each pretrained model, a list of available options is displayed.
#
Classification parameters
#
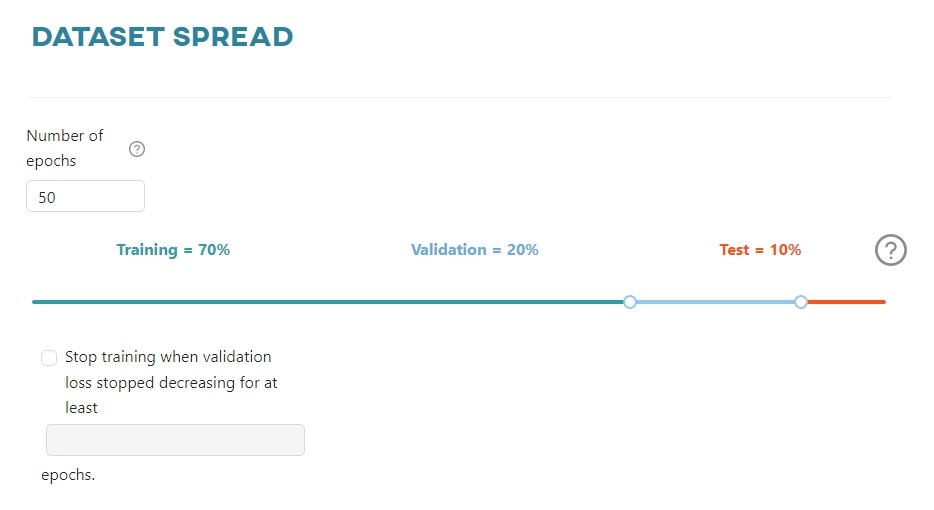
Dataset spread - Keras/PyTorch
In this section you can set:
- the number of model training epochs,
- the percentage division of the dataset into training, validation and test sets.
Optionally, you can set the Early Stop parameter. This means that the model can stop training early if the loss value does not decrease during the specified number of epochs.
#
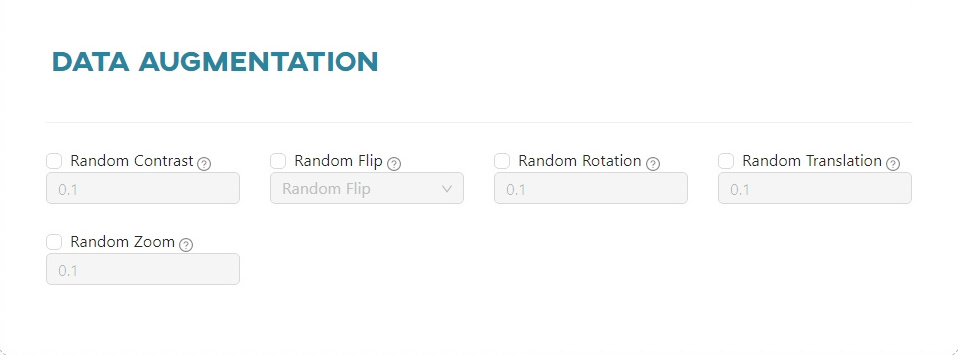
Data augmentation - Keras
In this section you can set the following parameters:
Random Contrast- randomly adjusts the contrast of the image.Random Flip- randomly flips the image horizontally and/or vertically based on the mode attribute.- Vertical
- Horizontal
- Horizontal and vertical
Random Rotation- randomly rotates the image, filling in the empty space.Random Translation- randomly translates the image, filling in the empty space.Random Zoom- randomly zooms in or out on each axis of the image independently, filling in the empty space.
#
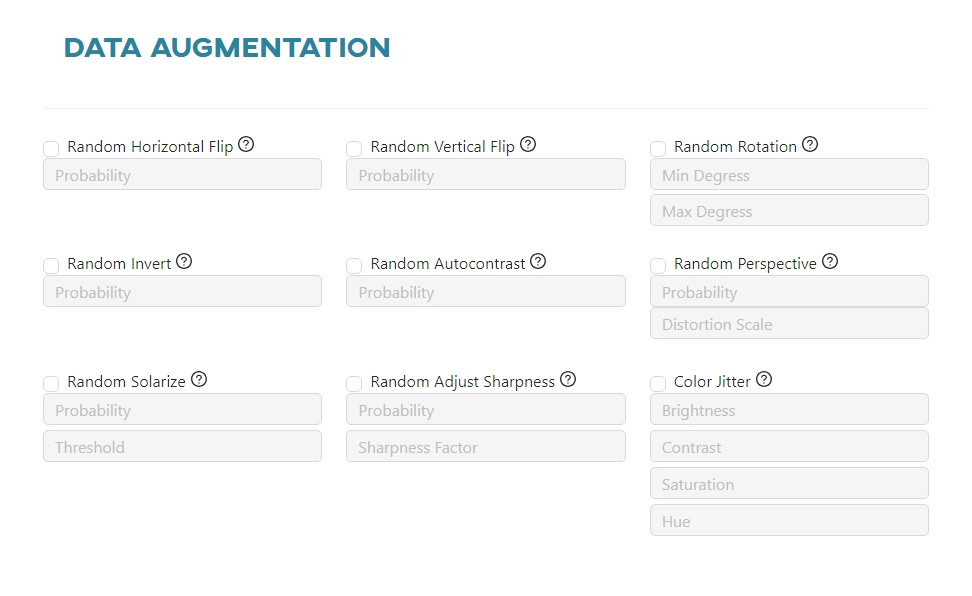
Data augmentation - PyTorch
In this section you can set the following parameters:
Random Horizontal Flip- randomly flips the image horizontally with a given probability.Random Vertical Flip- randomly flips the image vertically with a given probability.Random Rotation- randomly rotates each image by angle, filling in the empty space.Random Invert- randomly inverts the colors of the image with a given probability.Random Autocontrast- randomly autocontrasts the pixels of the image with a given probability.Random Perspective- performsa random perspective transformation of the image with a given probability.Random Solarize- randomly solarizes the image with a given probability by inverting all pixel values above a threshold.Random Adjust Sharpness- randomly adjusts the sharpness of the image with a given probability.Color Jitter- randomly changes the brightness, contrast, saturation and hue of the image.
#
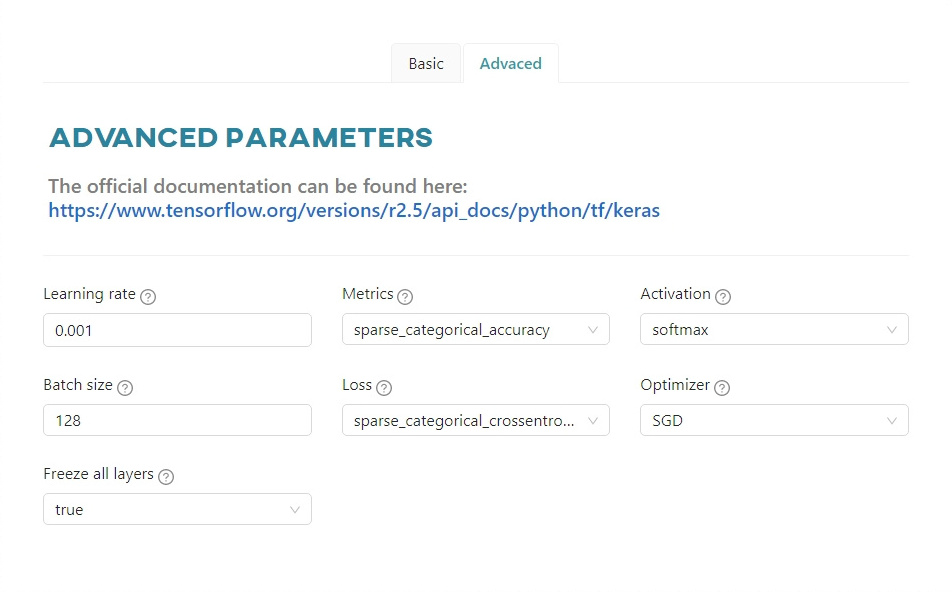
Advanced parameters - Keras
The Advanced tab contains advanced parameters, details of which can be found in the documentation of the selected framework:
Learning rate- controls how much to change the model in response to the estimated error each time the model weights are updated.Metrics- a function that is used to evaluate the performance of your model. Metric functions are similar to loss functions, except that the results of evaluating a metric are not used when training the model.Activation- a function that is a mathematical “gate” between the input feeding the current neuron and its output going to the next layer.Batch size- the number of training examples utilized in one iteration. The maximum value is determined by the model configuration.Loss- a method of evaluating how well a specific algorithm models the given data.Optimizer- an algorithm used to minimize the error function (loss function) and maximize production efficiency.Freeze all layers- freezing prevents the weights of a neural network layer from being modified during the backward pass of training. You progressively 'lock-in' the weights for each layer to reduce the amount of computation in the backward pass and reduce training time.
#
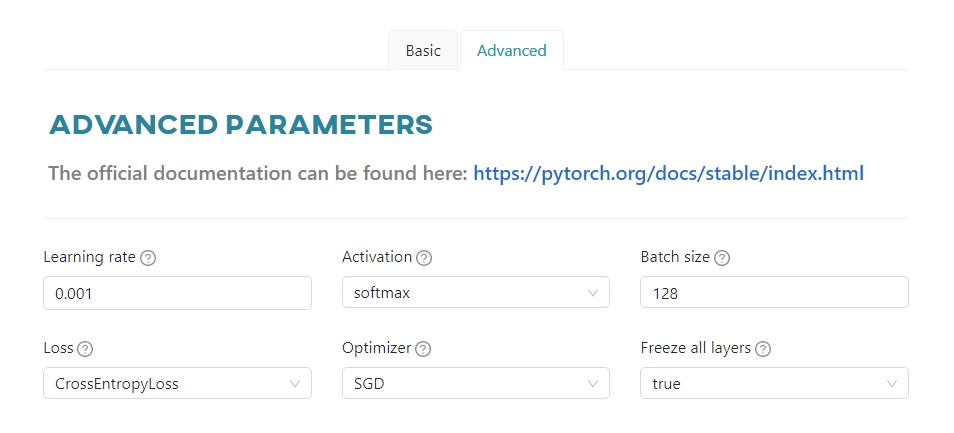
Advanced parameters - PyTorch
Learning rate- controls how much to change the model in response to the estimated error each time the model weights are updated.Activation- a function that is a mathematical “gate” between the input feeding the current neuron and its output going to the next layer.Batch size- the number of training examples utilized in one iteration. The maximum value is determined by model configuration.Loss- a method of evaluating how well specific algorithm models the given data.Optimizer- an algorithm used to minimize the error function (loss function) and maximize the production efficiency.Freeze all layers- freezing prevents the weights of a neural network layer from being modified during the backward pass of training. You progressively 'lock-in' the weights for each layer to reduce the amount of computation in the backward pass and decrease training time.
#
Object detection parameters
#
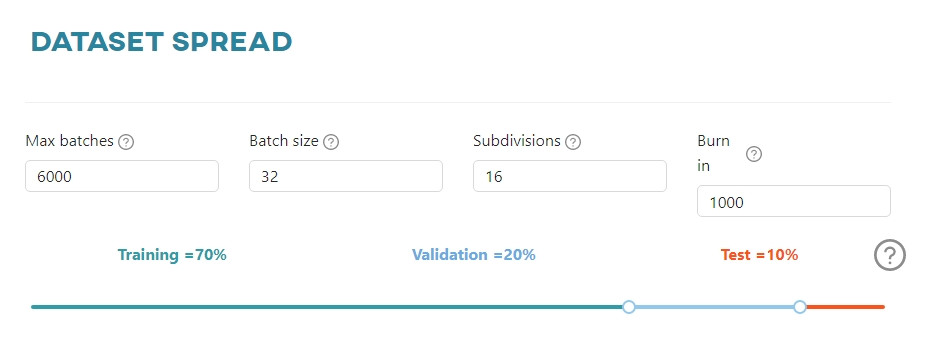
Dataset spread - Darknet
Here you can set parameters referring to dataset usage:
Max batches- the number of iterations, where 1 iteration means processing of 64 images and we call it 1 batch.Batch size- the number of training examples used in one iteration. The maximum value is determined by the configuration of the model.Subdivisions- the batch (64) is subdivided by the input value, to get image blocks. The image blocks are run in parallel on the GPU.Burn in- the first n batches (iterations) will increase the learning rate according to the formula:
current\_learning\_rate = learning\_rate ⋅ \left({\frac{iterations}{n}}\right)^{power} , where power=4 by default.
Please note that this parameter cannot be higher than the max batches value.
- Percentage breakdown of the dataset into training, validation and test sets.
#
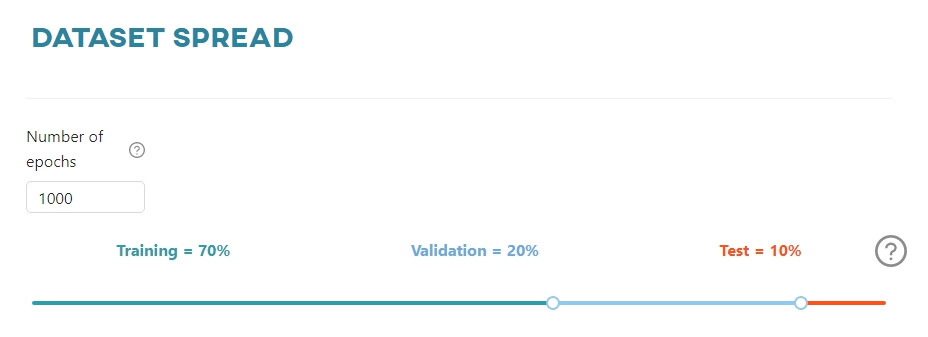
Dataset spread - Tensorflow
In this section you can set:
- the number of model training epochs,
- the percentage division of the dataset into training, validation and test sets.
#
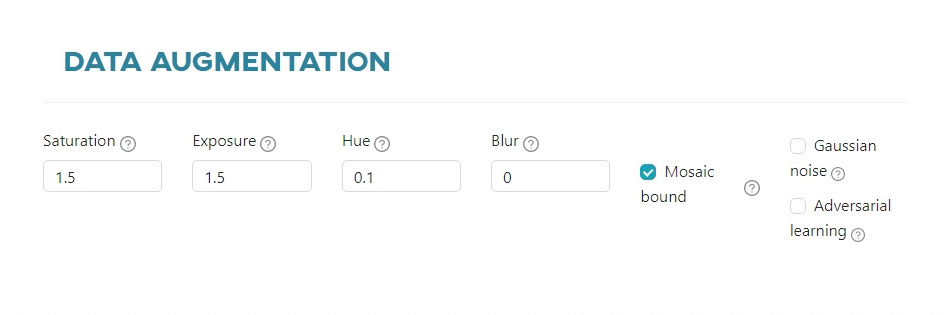
Data augmentation - Darknet
Here you can set how your additional data will be created:
Saturation- randomly changes the saturation of the image.Exposure- randomly changes the exposure (brightness) of the image.Hue- randomly changes the hue (color) of the image.Blur- randomly applies blur 50% of the time. If 1 - will blur the background except objects with blur_kernel=31, if >1 - will blur the whole image with blur_kernel=blur.Mosaic bound- limits the size of objects when Mosaic is selected (does not allow bounding boxes to leave the borders of their images when Mosaic-data-augmentation is used).Gaussian noise- randomly adds Gaussian noise to the image.Adversarial learning- changes all detected objects so that they appear different from the neural network's point of view. Consequently, a neural network launches an adversarial attack on itself.
#
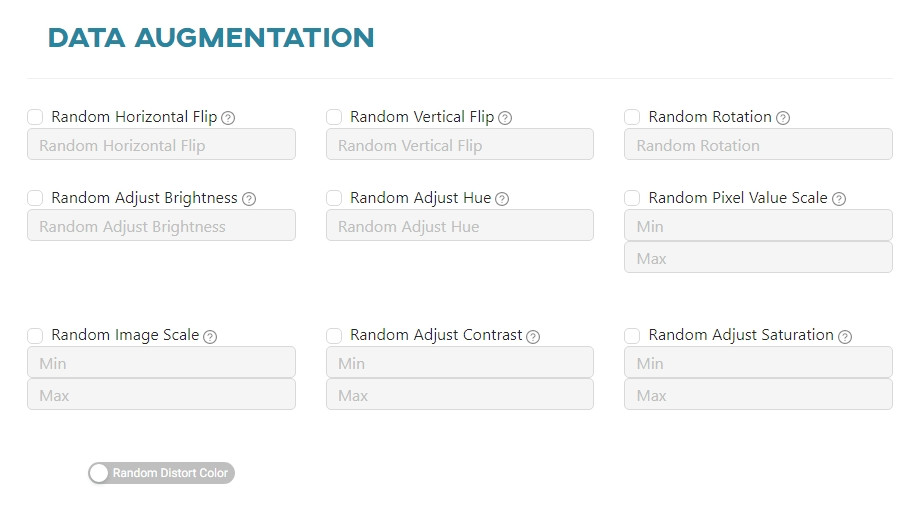
Data augmentation - Tensorflow
Here you can set how your additional data will be created:
Random Horizontal Flip- randomly flips the image horizontally.Random Vertical Flip- randomly flips the image vertically.Random Rotation- randomly rotates the image.Random Adjust Brightness- randomly adjusts the brightness of the image.Random Adjust Hue- randomly adjusts the hue of the image.Random Pixel Value Scale- randomly scales the pixel values of the image.Random Image Scale- randomly scales the size of the image.Random Adjust Contrast- randomly adjusts the contrast of the image.Random Adjust Saturation- randomly adjusts the saturation of the image.Random Distort Color- randomly distorts color of the image.
#
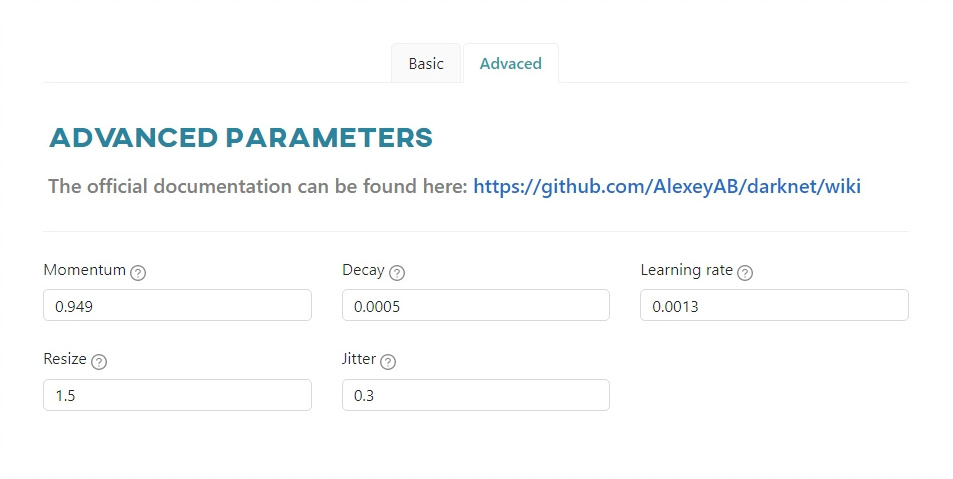
Advanced parameters - Darknet
The Advanced tab contains advanced parameters, a detailed description of which can be found in the documentation of the selected framework:
Momentum- accumulation of movement, how much the history affects the further change of weights (optimizer).Decay- a weaker updating of the weights for typical features, it eliminates disbalance in dataset (optimizer).Learning rate- controls how much to change the model in response to the estimated error each time the model weights are updated.Resize- randomly resize the image in the range of[1 / 1.5 - 1.5x]. The minimum value is1.1and the maximum value is10. We recommend not to exceed the value of2.0.Jitter- randomly crops and resizes images with changing aspect ratio in the range from x(1 - 2 \cdot jitter) \rightarrow x(1 + 2 \cdot jitter) (data augmentation parameter is used only from the last layer).
#
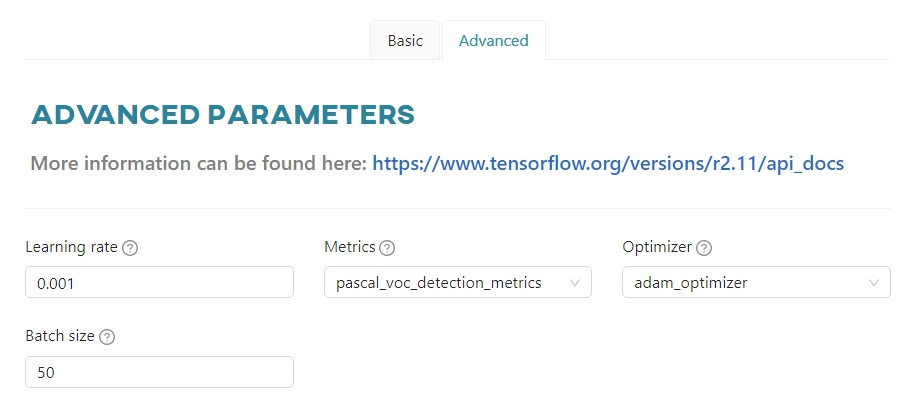
Advanced parameters - Tensorflow
Learning rate- controls how much to change the model in response to the estimated error each time the model weights are updated.Metrics- a metric is a function that is used to evaluate the performance of your model. Metric functions are similar to loss functions, except that the results of evaluating a metric are not used when training the model.Optimizer- algorithm used to minimize an error function (loss function) and maximize the production efficiency.Batch size- the number of training examples used in one iteration. The maximum value is determined by the configuration of the model.
#
Automatic Parametrization
To simplify and speed up your model testing process, we have created an “automatic model testing” feature. Instead of going through a an extensive multi-choice form, you can focus on accuracy while we set the rest of the parameters for an optimal training process.
Ready to try it out? Add a model, select a training type, pick categories, merge categories, turn on Configure automatically option and select the accuracy level that satisfies you. Then run the entire experiment on the automatically adjusted settings.
#
How to read the results
The effectiveness of the training can be evaluated when it is stopped. In the Automatic setting, training will stop for one of two reasons:
The model has reached the accuracy you were looking for within a reasonable number of epochs. Your dataset provides a good amount of information and the parameters are good. You should still be cautious and do some additional testing – such a result also means that your model has reached a level of accuracy that it will not be able to maintain consistently.
The model has reached the maximum number of epochs allowed without the expected results. This most likely means that your dataset needs improvement. Consider adding more images or checking the existing ones for oddly placed annotations or incorrect categories. If this does not help, consider manual configuration and adjust the parameters until you are satisfied with the results.
In either case, we will provide you with a model with the highest accuracy achieved.