Tworzenie modelu
Tworzenie modelu można rozpocząć, klikając przycisk Dodaj nowy model w widoku listy modeli.
Aby uzyskać wizualny przewodnik, zapoznaj się z samouczkiem na naszym kanale Youtube:
Tworzenie modelu składa się z następujących kroków:
- Wybór rodzaju treningu
- Wybór kategorii
- Scalanie kategorii
- Parametryzacja (różni się w zależności od wybranego frameworka)
- Uruchomienie treningu
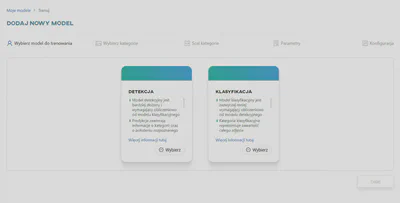
Wybierz rodzaj treningu
Najpierw wybierz typ modelu - Detekcja lub Klasyfikacja. Po dokonaniu wyboru zostaniesz przeniesiony/a do następnego kroku.
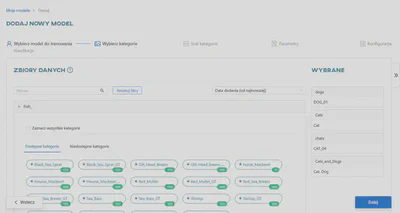
Wybieranie kategorii
W tym kroku wybierz kategorie, których chcesz użyć do trenowania modelu sieci neuronowej. Kategorie są wymienione pod nazwą każdego dostępnego zbioru danych. Każda kategoria musi zawierać co najmniej 3 obrazy, aby sieć mogła na niej działać.
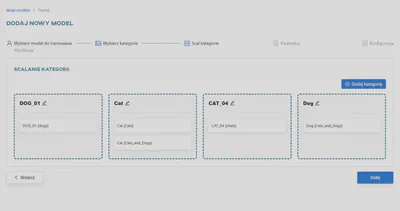
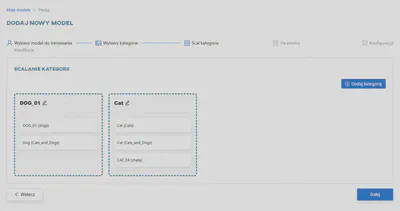
Scalanie kategorii
Kategorie wybrane w poprzednim kroku można łączyć ze sobą. Cały proces został opisany bardziej szczegółowo w artykule Scalanie kategorii.
Wybierz sposób parametryzacji
Wprowadź nazwę modelu (maksymalnie 50 znaków; dozwolone są tylko litery alfabetu łacińskiego, cyfry i myślniki) i wybierz framework, który ma być używany do treningu z listy dostępnych frameworków.
Do wyboru są dwa rodzaje parametryzacji:
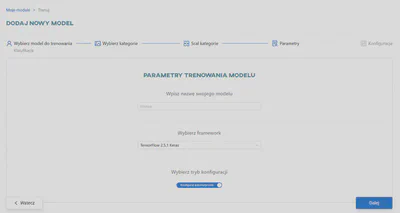
Ręczna parametryzacja
Opcje podstawowe
Podstawowa konfiguracja modelu składa się z:
- Szablon (opcjonalnie),
- Pretrenowany model.
W przypadku wybrania pretrenowanego modelu wszystkie pola parametrów zostaną wypełnione wartościami domyślnymi, które są najbardziej optymalne dla danego wstępnie wytrenowanego modelu. Istnieje możliwość zmiany tych wartości, ale radykalna zmiana parametrów domyślnych może zmniejszyć wydajność wytrenowanego modelu.
Oto krótkie wyjaśnienie każdego pretrenowanego modelu:
Darknet
YOLOv4.conv.137 - Wariant modelu wykrywania obiektów YOLO (You Only Look Once) ze 137 warstwami konwolucyjnymi. Jest znany ze swojej szybkości i dokładności.
YOLOv4-tiny.conv - Mniejsza i szybsza wersja YOLOv4 do wykrywania obiektów w czasie rzeczywistym przy zmniejszonych wymaganiach obliczeniowych.
Tensorflow 2.11
SSDMobileNetV2 - połączenie dwóch popularnych architektur, SSD (Single Shot MultiBox Detector) i MobileNetV2. Oferuje równowagę między szybkością i dokładnością.
SSDMobileNetV1FPN - Podobnie jak SSDMobileNetV2, model ten łączy SSD ze szkieletem MobileNetV1, ale zawiera również Feature Pyramid Network (FPN). FPN zwiększa zdolność modelu do wykrywania obiektów w różnych skalach, poprawiając dokładność.
EfficientDetD0 i EfficientDetD1 - warianty modelu EfficientDet, który został zaprojektowany do wydajnego wykrywania obiektów. Wersje D0 i D1 reprezentują różne rozmiary modelu i kompromisy obliczeniowe. D0 jest lżejszy i szybszy, podczas gdy D1 oferuje nieco wyższą dokładność kosztem większej złożoności.
CenterNetResnet50V1FPN i CenterNetResnet50V2 - CenterNet to model wykrywania obiektów, który koncentruje się na wykrywaniu punktu środkowego obiektów na obrazach. Te konkretne wersje wykorzystują architekturę ResNet50 w wariancie V1 lub V2 i zawierają sieć piramid cech (FPN) w celu lepszego wykrywania i lokalizacji obiektów.
TensorFlow 2.5.1 Keras
DenseNet121, DenseNet169, DenseNet201, DenseNet161 - są to odmiany architektury DenseNet, znanej z gęstej łączności między warstwami. Są one skuteczne w zadaniach klasyfikacji obrazów, a ich liczba wskazuje na głębokość i złożoność modelu.
InceptionResNetV2 i InceptionV3 - modele te łączą w sobie cechy architektur Google Inception i ResNet. Są one używane do klasyfikacji obrazów i zadań ekstrakcji cech, przy czym InceptionResNetV2 jest bardziej zaawansowaną i głębszą wersją.
MobileNet i MobileNetV2 - są to lekkie architektury konwolucyjnych sieci neuronowych zaprojektowane dla urządzeń mobilnych i wbudowanych. MobileNetV2 jest ulepszoną wersją oryginalnego MobileNet.
NASNetLarge i NASNetMobile - modele te zostały opracowane w ramach badań nad architekturą neuronową. NASNetLarge jest siecią na dużą skalę, podczas gdy NASNetMobile jest mniejszą, przyjazną dla urządzeń mobilnych wersją. Oba mogą być wykorzystywane do różnych zadań związanych z wizją komputerową.
Modele ResNet (ResNet18, ResNet34, ResNet50, ResNet101, ResNet152) - są to członkowie rodziny ResNet (Residual Network) o różnej głębokości. Są one znane z pomijania połączeń i są szeroko stosowane do klasyfikacji obrazów i innych zadań wizyjnych.
VGG16 i VGG19 - modele VGG (Visual Geometry Group) są znane ze swojej prostoty i głębokiej architektury. VGG16 ma 16 warstw wagowych, a VGG19 ma 19 warstw wagowych. Są one używane do klasyfikacji obrazów i ekstrakcji funkcji.
Xception - Głęboka architektura sieci konwolucyjnej, która kładzie nacisk na separowalne głębokościowo konwolucje. Przeznaczona jest do klasyfikacji obrazów i zadań ekstrakcji cech.
EfficientNetB0, B1, B2, B3, B4, B5 - Modele te są częścią rodziny EfficientNet, która wykorzystuje złożone skalowanie w celu zrównoważenia rozmiaru modelu i wydajności. Liczba wskazuje różne współczynniki skalowania i poziomy złożoności, przy czym B0 jest najmniejszy, a B5 jest większy i bardziej wydajny.
PyTorch 1.8.1 i PyTorch 2.2.2
SqueezeNet1.0 i SqueezeNet1.1 - modele SqueezeNet zostały zaprojektowane z myślą o wydajnym wnioskowaniu i wdrażaniu modeli. Osiągają wysoką dokładność przy zmniejszonym rozmiarze modelu, dzięki czemu nadają się do urządzeń o ograniczonych zasobach. SqueezeNet1.1 jest nieznacznym ulepszeniem w stosunku do SqueezeNet1.0.
GoogLeNet - znany również jako architektura Inception, GoogLeNet jest znany z wielu modułów inception, które pozwalają mu skutecznie przechwytywać funkcje w różnych skalach. Służy do klasyfikacji obrazów i innych zadań wizyjnych.
ShuffleNetV2_x1.0 i ShuffleNetV2_x0.5 - ShuffleNet został zaprojektowany z myślą o wydajnym wnioskowaniu i wykorzystaniu pamięci. Modele te obejmują operacje tasowania kanałów, a x1.0 i x0.5 odnoszą się do różnych skal modeli. x0.5 to lżejsza wersja.
MobileNetV3_large i MobileNetV3_small - są to odmiany MobileNetV3, zaprojektowane dla urządzeń mobilnych i brzegowych. Zapewniają równowagę między dokładnością a rozmiarem modelu, przy czym duża wersja jest bardziej wydajna, a mała jest lżejsza.
ResNeXt50_32x4d i ResNeXt101_32x8d - ResNeXt to wariant ResNet, który wykorzystuje zgrupowane zwoje. Liczby 32x4d i 32x8d odnoszą się do liczby grup i ich szerokości. Większa liczba oznacza bardziej złożony i wydajny model.
WideResNet50_2 i WideResNet101_2 - modele WideResNet są oparte na ResNet, ale mają zwiększoną szerokość. Zapewniają one lepszą wydajność poprzez zwiększenie liczby filtrów w każdej warstwie. Liczby 50_2 i 101_2 oznaczają głębokość i szerokość modeli.
MnasNet1.0 i MnasNet0.5 - modele MnasNet są przeznaczone dla urządzeń mobilnych. 1.0 i 0.5 wskazują rozmiar modelu, gdzie 1.0 to większy wariant, podczas gdy 0.5 jest lżejszy.
Jeśli chcesz zachować wartości domyślne, możesz przejść do następnego kroku - Rozpocznij trening.
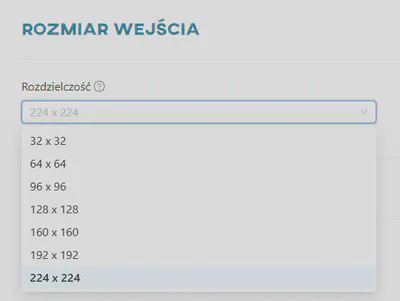
Rozmiar wejściowy
Rozmiar wejściowy reprezentuje rozdzielczość obrazów przetwarzanych przez sieć neuronową. Jest to rozdzielczość, której sieć oczekuje jako danych wejściowych. Obrazy z zestawów danych, które będą używane w procesie treningu, będą również skalowane do tej rozdzielczości. Dla każdego wstępnie wytrenowanego modelu wyświetlana jest lista dostępnych opcji.
Parametry klasyfikacji
Rozkład zbioru danych - Keras/PyTorch
W tej sekcji można ustawić
- liczbę epok szkolenia modelu,
- procentowy podział zbioru danych na zestawy treningowe, walidacyjne i testowe.
Opcjonalnie można ustawić parametr wczesnego zatrzymania. Oznacza to, że model może wcześniej przerwać szkolenie, jeśli wartość straty nie zmniejszy się w określonej liczbie epok.

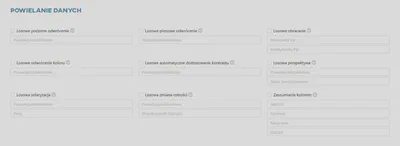
Powielanie danych - Keras
W tej sekcji można ustawić następujące parametry:
Losowy kontrast- losowo dostosowuje kontrast obrazu.Losowe przerzucanie- losowo przerzuca obraz w poziomie i/lub w pionie w oparciu o atrybut trybu.- Pionowe
- Poziome
- Poziome i pionowe
Losowe obracanie- losowo obraca obraz, wypełniając puste miejsce.Losowe przesunięcie- losowo przesuwa obraz, wypełniając puste miejsce.Losowe przybliżanie- losowo przybliża lub oddala obraz na każdej osi niezależnie, wypełniając puste miejsce.

Powielanie danych - PyTorch
W tej sekcji można ustawić następujące parametry:
Losowe poziome odwrócenie- losowo odwraca obraz w poziomie z określonym prawdopodobieństwem.Losowe pionowe odwrócenie- losowo odwraca obraz w pionie z określonym prawdopodobieństwem.Losowe obracanie- losowo obraca każdy obraz o kąt, wypełniając puste miejsce.Losowe odwrócenie koloru- losowo odwraca kolory obrazu z określonym prawdopodobieństwem.Losowe automatyczne dostosowanie kontrastu- losowo autokontrastuje piksele obrazu z określonym prawdopodobieństwem.Losowa perspektywa- losowo przekształca perspektywę obrazu z określonym prawdopodobieństwem.Losowa solaryzacja- losowo solaryzuje obraz z określonym prawdopodobieństwem, odwracając wszystkie wartości pikseli powyżej progu.Losowa zmiana ostrości- losowo dostosowuje ostrość obrazu z określonym prawdopodobieństwem.Zaszumianie kolorem- losowo zmienia jasność, kontrast, nasycenie i odcień obrazu.
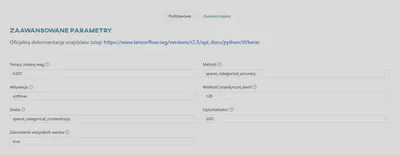
Parametry zaawansowane - Keras
Zakładka Zaawansowane zawiera zaawansowane parametry, których szczegóły można znaleźć w dokumentacji wybranego frameworka:
Tempo zmiany wag- Determinuje poziom modyfikacji wag (o większe lub mniejsze wartości) modelu w odpowiedzi na szacowaną stratę za każdym razem, gdy wagi tego modelu są aktualizowane.Metryki- Metryka to funkcja służąca do oceny wydajności modelu. Funkcje metryk są podobne do funkcji straty, z tym wyjątkiem, że wyniki oceny metryki nie są używane podczas trenowania modelu.Aktywacja- Funkcja będąca matematyczną ‘bramą’ między wejściem zasilającym aktualny neuron a jego wyjściem, które trafia do kolejnej warstwy. Wprowadza nieliniowość do modelu, umożliwiając mu uczenie się bardziej złożonych relacji między danymi.Wielkość pojedynczej partii- Liczba obrazów tworzących jedną partię danych treningowych, przetwarzanych jednocześnie przez jednostkę obliczeniową.Strata- Funkcja straty, czyli algorytm mierzący błąd pomiędzy predykcjami modelu a poprawnymi wartościami danych podczas treningu.Optymalizator- Algorytm używany do aktualizacji wag modelu w trakcie procesu uczenia w celu minimalizacji funkcji straty. Optymalizator analizuje gradient funkcji straty i dostosowuje wagi modelu w taki sposób, aby zmniejszyć wartość funkcji straty.Zamrożenie wszystkich warstw- Zamrażanie zapobiega modyfikacji wag danych warstw sieci neuronowej podczas kolejnych iteracji treningu. Dobrą praktyką jest stopniowe ‘blokowanie’ wag dla każdej warstwy, aby zwiększyć dokładność modelu, zmniejszyć ilość obliczeń i skrócić czas treningu.
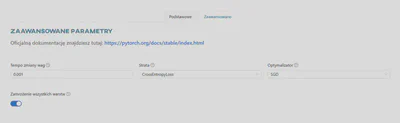
Parametry zaawansowane - PyTorch
Tempo zmiany wag- Determinuje poziom modyfikacji wag (o większe lub mniejsze wartości) modelu w odpowiedzi na szacowaną stratę za każdym razem, gdy wagi tego modelu są aktualizowane.Aktywacja- Funkcja będąca matematyczną ‘bramą’ między wejściem zasilającym aktualny neuron a jego wyjściem, które trafia do kolejnej warstwy. Wprowadza nieliniowość do modelu, umożliwiając mu uczenie się bardziej złożonych relacji między danymi.Wielkość pojedynczej partii- Liczba obrazów tworzących jedną partię danych treningowych, przetwarzanych jednocześnie przez jednostkę obliczeniową.Strata- Funkcja straty, czyli algorytm mierzący błąd pomiędzy predykcjami modelu a poprawnymi wartościami danych podczas treningu.Optymalizator- Algorytm używany do aktualizacji wag modelu w trakcie procesu uczenia w celu minimalizacji funkcji straty. Optymalizator analizuje gradient funkcji straty i dostosowuje wagi modelu w taki sposób, aby zmniejszyć wartość funkcji straty.Zamrożenie wszystkich warstw- Zamrażanie zapobiega modyfikacji wag danych warstw sieci neuronowej podczas kolejnych iteracji treningu. Dobrą praktyką jest stopniowe ‘blokowanie’ wag dla każdej warstwy, aby zwiększyć dokładność modelu, zmniejszyć ilość obliczeń i skrócić czas treningu.
Parametry detekcji
Rozkład zbioru danych - Darknet
Tutaj można ustawić parametry odnoszące się do wykorzystania zbioru danych:
Maksymalna ilość partii danych- Maksymalna liczba partii danych, która zostanie przetworzona w ramach całego treningu. Wielkość każdej partii określa inny parametr. Należy zaznaczyć, iż pojęcie to różni się od ’epoki’ używanej w kontekście innych frameworków.Wielkość pojedynczej partii- Liczba obrazów tworzących jedną partię danych treningowych. Maksymalna ilość partii do przetworzenia w ramach całego treningu jest określona przez osobny parametr.Ilość bloków w partii- Partia danych jest dzielona przez wartość z tego parametru, aby uzyskać zadaną ilość równych bloków obrazów. Bloki obrazów są przetwarzane równolegle na jednostce obliczeniowej.Epoki rozgrzewkowe- W pierwszych n partiach zwiększa się szybkość uczenia według wzoru:
$current\_learning\_rate = learning\_rate ⋅ \left({\frac{iterations}{n}}\right)^{power}$ , gdzie domyślnie jest power=4.
Należy pamiętać, że parametr ten nie może być wyższy niż maksymalna ilość partii danych.
Procentowy podział zbioru danych na zestawy treningowe, walidacyjne i testowe.

Rozkład zbioru danych - Tensorflow
W tej sekcji można ustawić:
- liczbę epok szkolenia modelu,
- procentowy podział zbioru danych na zestawy treningowe, walidacyjne i testowe.

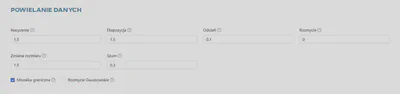
Powielanie danych - Darknet
Tutaj można ustawić sposób tworzenia dodatkowych danych:
Nasycenie- losowo zmienia nasycenie obrazu.Ekspozycja- losowo zmienia ekspozycję (jasność) obrazu.Odcień- losowo zmienia odcień (kolor) obrazu.Rozmycie- losowo stosuje rozmycie przez 50% czasu. Jeśli 1 - rozmyje tło z wyjątkiem obiektów z blur_kernel=31, jeśli >1 - rozmyje cały obraz z blur_kernel=blur.Zmiana rozmiaru- losowo zmienia rozmiar obrazu w zakresie [1 / 1.5 - 1.5x]. Minimalna wartość to 1.1, maksymalna wartość to 10. Zalecamy nie przekraczać wartości 2.0.Szum- losowo przycina i zmienia rozmiar obrazów ze zmieniającym się współczynnikiem proporcji od x(1-2jitter) do x(1+2jitter) (parametr rozszerzenia danych jest używany tylko z ostatniej warstwy).Mozaika graniczna- multiplikuje obraz tworząc mozaikę (4 obrazy w jednym).Rozmycie Gaussowskie- losowo dodaje rozmycie Gaussowskie do przetwarzanych obrazów.
Powielanie danych - Tensorflow
Tutaj można ustawić sposób tworzenia dodatkowych danych:
Losowe poziome odwrócenie- losowo odwraca obraz w poziomie.Losowe pionowe odwrócenie- losowo odwraca obraz w pionie.Losowe obracanie- losowo obraca obraz.Losowa zmiana jasności- losowo dostosowuje jasność obrazu.Losowa zmiana odcienia- losowa zmiana odcienia obrazu.Losowe skalowanie wartości pikseli- losowe skalowanie wartości pikseli obrazu.Losowe skalowanie obrazu- losowe skalowanie rozmiaru obrazu.Losowa korekta kontrastu- losowa korekta kontrastu obrazu.Losowa korekta nasycenia- losowo dostosowuje nasycenie obrazu.Rozmycie Gaussowskie- losowo dodaje rozmycie Gaussowskie do przetwarzanych obrazów.
Parametry zaawansowane - Darknet
Zakładka Zaawansowane zawiera zaawansowane parametry, których szczegółowy opis można znaleźć w dokumentacji wybranego frameworka:
Pęd- W kontekście optymalizacji gradientowej odnosi się do techniki używanej do przyspieszenia procesu uczenia poprzez akumulację historycznego gradientu. Podana wartość określa, jak bardzo historia wpływa na dalszą zmianę wag.Spadek- Słabsza aktualizacja wag dla typowych cech, eliminuje nierównowagę w zbiorze danych w celu uniknięcia przetrenowania.Tempo zmiany wag- Determinuje poziom modyfikacji wag (o większe lub mniejsze wartości) modelu w odpowiedzi na szacowaną stratę za każdym razem, gdy wagi tego modelu są aktualizowane.Uczenie przeciwstawne- Zmienia wszystkie predykowane obiekty, aby były różne z punktu widzenia sieci neuronowej. Sieć neuronowa przeprowadza na sobie ‘atak’, aby stać się bardziej odporną na manipulacje i dane mogące wprowadzać ją w błąd.
Parametry zaawansowane - Tensorflow
Tempo zmiany wag- Determinuje poziom modyfikacji wag (o większe lub mniejsze wartości) modelu w odpowiedzi na szacowaną stratę za każdym razem, gdy wagi tego modelu są aktualizowane.Metryki- Metryka to funkcja służąca do oceny wydajności modelu. Funkcje metryk są podobne do funkcji straty, z tym wyjątkiem, że wyniki oceny metryki nie są używane podczas trenowania modelu.Optymalizator- Algorytm używany do aktualizacji wag modelu w trakcie procesu uczenia w celu minimalizacji funkcji straty. Optymalizator analizuje gradient funkcji straty i dostosowuje wagi modelu w taki sposób, aby zmniejszyć wartość funkcji straty.Wielkość pojedynczej partii- Liczba obrazów tworzących jedną partię danych treningowych, przetwarzanych jednocześnie przez jednostkę obliczeniową.
Automatyczna parametryzacja
Aby uprościć i przyspieszyć proces testowania modelu, stworzyliśmy funkcję „automatycznego testowania modelu”. Zamiast przechodzić przez obszerny formularz wielokrotnego wyboru, możesz skupić się na dokładności, podczas gdy my ustawimy pozostałe parametry dla optymalnego procesu szkolenia.
Jesteś gotowy, aby to wypróbować? Dodaj model, wybierz rodzaj treningu, wybierz kategorie, scal je, włącz opcję Konfiguruj automatycznie i wybierz satysfakcjonujący Cię poziom dokładności. Następnie uruchom cały eksperyment na automatycznie dostosowanych ustawieniach.
Jak odczytać wyniki
Skuteczność szkolenia można ocenić po jego zatrzymaniu. W ustawieniu automatycznym trening zostanie zatrzymany z jednego z dwóch powodów:
Model osiągnął oczekiwaną dokładność w rozsądnej liczbie epok. Zbiór danych zapewnia dużą ilość informacji, a parametry są dobre. Należy jednak zachować ostrożność i przeprowadzić dodatkowe testy - taki wynik oznacza również, że model osiągnął poziom dokładności, którego nie będzie w stanie konsekwentnie utrzymywać.
Model osiągnął maksymalną dozwoloną liczbę epok bez oczekiwanych wyników. Najprawdopodobniej oznacza to, że zestaw danych wymaga poprawy. Rozważ dodanie większej liczby obrazów lub sprawdzenie istniejących pod kątem dziwnie umieszczonych adnotacji lub nieprawidłowych kategorii. Jeśli to nie pomoże, rozważ ręczną konfigurację i dostosuj parametry, aż będziesz zadowolony/a z wyników.
W obu przypadkach dostarczymy model o najwyższej osiągniętej dokładności.