Detektor rasy psów
W tym samouczku zbudujesz model wykrywania zdolny do rozpoznawania ras psów w klatkach wideo.
Dowiesz się, jak
- dodawać obrazy i adnotacje oddzielnie,
- trenować model przy użyciu frameworka Darknet,
- testować wykrywacz w czasie rzeczywistym.
Aby stworzyć model, użyj publicznie dostępnego zbioru danych Stanford Dogs, który zawiera 20 580 obrazów 120 ras psów. Zbiór danych składa się z obrazów i adnotacji zebranych w oddzielnych folderach.

Rozpakowywanie zbioru danych
Zbiór danych Stanford Dogs został zapisany w dwóch oddzielnych archiwach, tj. images i annotation z rozszerzeniem .tar. Chociaż nasz portal obsługuje takie rozszerzenia, nie można ich przesłać w tym samym czasie, co oznacza, że zdjęcia w zbiorze danych nie będą miały adnotacji. Należy je rozpakować i przesłać jako katalog.
Dodawanie zbioru danych
W sekcji Posiadane kliknij Dodaj nowy zbiór danych i stwórz nową kolekcję o nazwie my_dogs.
Kliknij Dodaj katalog, aby załadować katalog zawierający obrazy i adnotacje.
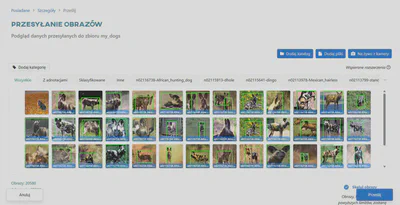
Po zatwierdzeniu obrazy z adnotacjami zostaną wyświetlone w miniaturkach. Kliknij przycisk Prześlij.
Można dodawać adnotacje obiektów do wykrywania w formacie Pascal VOC (pliki z rozszerzeniem .xml). Obraz i plik adnotacji muszą mieć tę samą nazwę - tylko wtedy można powiązać informacje o adnotacji na obrazie z samym obrazem.
Możesz samodzielnie połączyć dwa katalogi dla wybranej rasy psów w jeden katalog lub dodać obrazy i katalogi adnotacji w dwóch krokach podczas fazy przesyłania. Kolejność przesyłania nie ma znaczenia.
Tworzenie modelu
Aby utworzyć model, przejdź do sekcji Modele i kliknij Dodaj nowy model. Wybierz opcję Detekcja.
Wybierz zbiór danych my_dogs, aby użyć go do trenowania modelu.
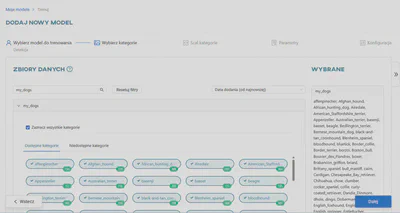
Następnym krokiem jest scalenie kategorii. Można zarządzać kategoriami obrazów w zbiorze danych. Opcja ta została opisana bardziej szczegółowo w artykule Tworzenie i trenowanie modeli. W tym samouczku nie jest konieczne zmienianie czegokolwiek w tym miejscu, więc kontynuuj klikając Dalej.
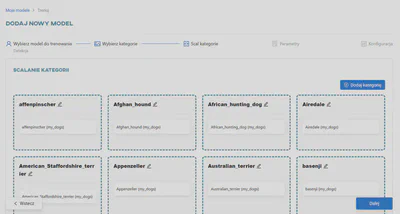
Teraz należy sparametryzować model. Wprowadź nazwę Dog Breed Detector i wybierz framework Darknet.
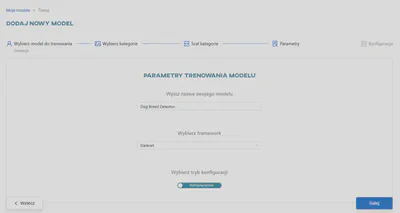
Zaakceptuj ustawienia domyślne lub zmień je według własnych upodobań w zakładce Tryb podstawowy i/lub Zaawansowany. Kliknij przycisk Rozpocznij trening.
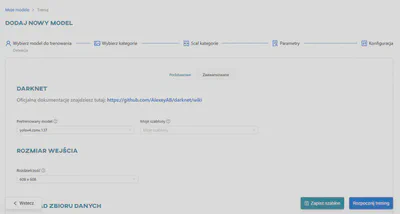
Proces treningu można wyświetlić w widoku Panelu głównego, w zakładce Powiadomienia lub w sekcji Modele.

Po zakończeniu szkolenia przekonwertuj model tak, aby był kompatybilny z NVIDIA Jetson Nano. Aby to zrobić, przejdź do sekcji Modele, najedź kursorem na ikonę koła zębatego i wybierz Szczegóły.
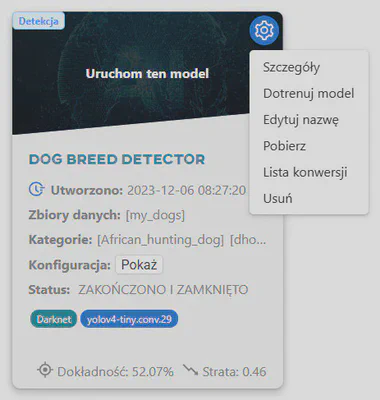
W sekcji Konwersja wybierz architekturę NVIDIA MAXWELL.
Testowanie modelu
Po zakończeniu konwersji przejdź do zakładki Wypożyczone urządzenia i wybierz Jetson Nano.
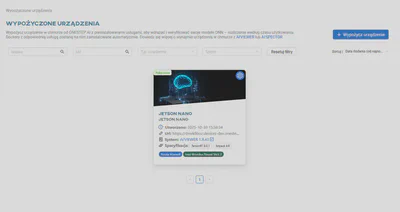
Spowoduje to otwarcie nowej karty przeglądarki z Artificial Intelligence Device Web Service (AIDWS), która zostanie uruchomiona na urządzeniu. Twój model będzie dostępny do pobrania na urządzenie.
Wyszukaj model i kliknij go, aby pobrać i uruchomić. Teraz możesz przesłać dane wejściowe, których użyjemy do przetestowania modelu. Aby to zrobić, kliknij przycisk Prześlij plik.
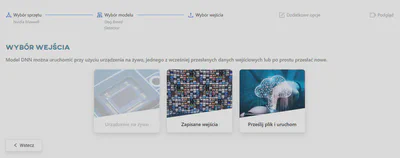
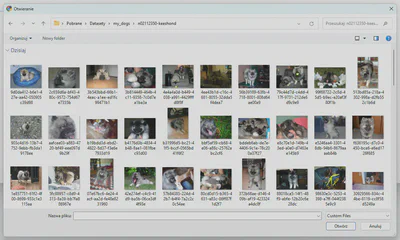
Wybierz pliki, które chcesz przesłać. Najpierw użyjemy pliku wideo.
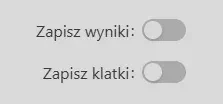
Po przesłaniu pliku wideo możesz zdecydować, czy chcesz zapisać wyniki i/lub zapisać klatki z wideo do nowego lub istniejącego zestawu danych. Kliknij Dalej, aby kontynuować.
Po przetworzeniu wideo aplikacja internetowa otworzy wbudowany odtwarzacz wideo.
Na filmie, który obejrzysz w odtwarzaczu, zobaczysz tagi ras przypisane do psów, które udało się znaleźć modelowi.
Wyniki
Tak wygląda klatka pracy modelu w odtwarzaczu multimedialnym aplikacji testowej:

Wyniki na przesłanych zdjęciach są podobne:


