Śledzenie wydajności modelu
Po udanym treningu można przejść do szczegółowego widoku modelu, aby sprawdzić jego statystyki lub dokonać dodatkowych konwersji.
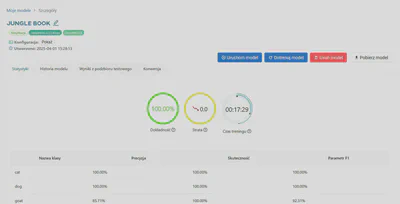
Górna sekcja wyświetla podstawowe informacje o modelu, takie jak:
- Nazwa wytrenowanego modelu
- Użyty framework
- Wybrany pretrenowany model
- Konfiguracja
- Data utworzenia
W sekcji Statystyki można zobaczyć ogólne informacje o wytrenowanym modelu:
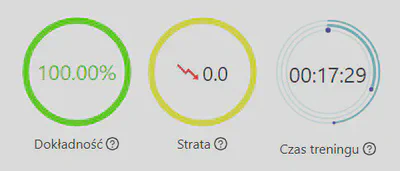
Statystyki obliczane są na podstawie funkcji dokładności/strat. Ich szczegółowy opis można znaleźć w dokumentacji wybranego frameworka.
- Dokładność - średnia precyzja modelu
- Strata - strata modelu
- Czas treningu
Dokładność klasyfikacji
Frameworki Keras i PyTorch
W przypadku modeli klasyfikacyjnych Keras i PyTorch dla każdej klasy obliczane są następujące miary dokładności:
- Precyzja - TP/(TP + FP)
- TP - True Positive, tj. liczba obrazów poprawnie przypisanych do danej klasy
- FP - False Positive, tj. liczba obrazów błędnie przypisanych do danej klasy.
- Skuteczność - TP/(TP + FN)
- FN - False Negative, tj. liczba zdjęć błędnie przypisanych do innej klasy
- Parametr F1 (2 _ precision _ recall / (precision + recall))

Następnie można przeanalizować interaktywne wykresy pokazujące zmianę wartości dokładności i strat w odniesieniu do epok.

Macierz błędów to kolejny element, który pomaga ocenić, czy model został poprawnie wytrenowany.
Macierz błędów to macierz N×N, w której kolumny odpowiadają prawidłowym klasom decyzyjnym, a wiersze odpowiadają rozpoznaniom wyuczonego modelu. Liczba na przecięciu kolumny i wiersza odpowiada liczbie obrazów z klasy kolumny, które zostały przypisane do klasy wiersza przez klasyfikator.

Zakres procentowy efektywności dla komórek diagonalnych (zakres jest odwrócony dla komórek nie-diagonalnych):
- Bardzo niska efektywność [0% - 20%]
- Niska efektywność [21% - 40%]
- Średnia efektywność [41% - 60%]
- Wysoka efektywność [61% - 80%]
- Bardzo wysoka efektywność [81% - 100%]
Komórki diagonalne reprezentują poprawne rozpoznania. Na przykład, obecny model poprawnie rozpoznał 85,71% zdjęć koni, co mieści się w zakresie bardzo wysokiej efektywności (80-100%), dlatego ta komórka została pokolorowana na zielono.
Każdy wiersz sumuje się do 100%. Na przykład, komórki po lewej stronie przedstawiają zdjęcia, na których tygrysy zostały rozpoznane jako koty, psy, kozy, konie i lwy. Te komórki zostały pokolorowane na zielono z powodu odwrócenia zakresu. Im mniej błędnych rozpoznań, tym skuteczniejszy jest model.
Mówiąc prościej: im więcej zielonych komórek w macierzy, tym lepiej wytrenowany model. Dla każdej komórki, która nie jest zielona, ogólna wydajność modelu spada zgodnie z zakresem procentowym pokazanym w komórce (i odpowiadającymi jej kolorami). Model jest całkowicie bezużyteczny, jeśli cała macierz jest czerwona.
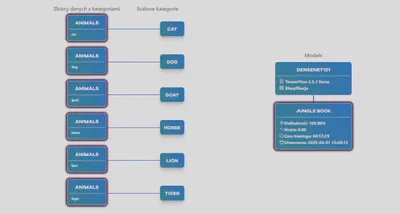
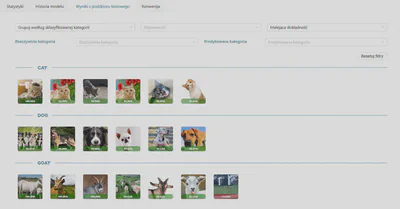
Dokładność detekcji
Framework Darknet
W przypadku modelu detekcji Darknet, dla każdej klasy możemy wyodrębnić następujące statystyki:
- Prawdziwie pozytywny wynik - tj. liczba detekcji prawidłowo rozpoznających daną klasę.
- Fałszywie pozytywny - liczba wykryć, które fałszywie rozpoznają daną klasę
- Średnia precyzja - PP/(PP + FP)
- Skuteczność - PP/(PP + FN)
- IOU = obszar nakładania się / obszar unii
- Obszar nakładania się - obszar nakładania się rzeczywistej i przewidywanej etykiety
- Obszar unii - obszar unii rzeczywistej i przewidywanej etykiety
- Wynik F1 - (2 _ precyzja _ skuteczność / (precyzja + skuteczność))

Framework Tensorflow
W przypadku modelu detekcji Tensorflow, dla każdej klasy możemy wyodrębnić następującą statystykę:
Średnia precyzja - PP/(PP + FP)

Następnie można przeanalizować interaktywne wykresy, które pokazują zmianę wartości precyzji i strat w każdej setnej iteracji.

Wartość precyzji jest obliczana po zakończeniu procesu Burn In (wstępnego treningu).