Jak stworzyć dobry model?
Tworzenie solidnego modelu sztucznej inteligencji do detekcji i/lub klasyfikacji obiektów na zdjęciach i filmach jest procesem wieloetapowym. Ten przewodnik przedstawi kluczowe kroki w celu opracowania wysokowydajnego modelu zdolnego do dokładnej identyfikacji i kategoryzacji obiektów.
1. Przygotowanie zbioru danych
Omówiliśmy już, jak stworzyć dobry zbiór danych tutaj.
2. Wybierz kategorie
Wybierz kategorie obiektów, które chcesz wykryć lub sklasyfikować. Upewnij się, że każda wybrana kategoria ma mniej więcej podobną liczbę obrazów. Do klasyfikacji potrzebujesz setek obrazów, podczas gdy do detekcji obiektów potrzebujesz tysięcy.
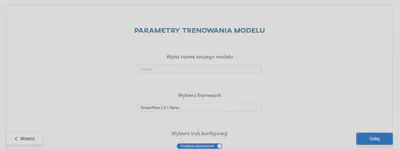
4. Wybór frameworka
Framework odnosi się do podstawowego ekosystemu oprogramowania lub biblioteki, która zapewnia niezbędne narzędzia, funkcje i infrastrukturę do budowania, szkolenia i wdrażania modeli AI. ONESTEP AI ma trzy frameworki do detekcji:
Darknet - przeczytaj oficjalną dokumentację tutaj
TensorFlow 2.11 - więcej informacji tutaj
Tensorflow 2.18 KerasCV
Oraz trzy frameworki do klasyfikacji:
TensorFlow 2.5.1 - przeczytaj oficjalną dokumentację tutaj
PyTorch 1.8.1 - przeczytaj oficjalną dokumentację tutaj
PyTorch 2.2.2 - przeczytaj oficjalną dokumentację tutaj
5. Parametryzacja
Wybierz odpowiednią metodę parametryzacji w oparciu o swoją wiedzę i wymagania. Dostępne są dwie opcje: Konfiguruj automatycznie i Konfiguruj ręcznie. Pierwsza opcja automatycznie dostosowuje ustawienia dla optymalnego procesu szkolenia i jest zalecana dla osób z ograniczoną wiedzą na temat sztucznej inteligencji. Druga opcja umożliwia samodzielne dostosowanie ustawień i jest zalecana dla osób z doświadczeniem w zakresie sztucznej inteligencji.
Modyfikacja parametrów może prowadzić do spadku wydajności modelu; jednak odwrotnie, domyślne parametry mogą nie być optymalne dla danego modelu.
6. Podstawowe parametry
Pretrenowany model - model uczenia maszynowego, który został wcześniej wytrenowany na dużym zbiorze danych. Nauczył się wyodrębniać cechy lub wzorce z danych wejściowych i może przewidywać lub wykonywać zadania związane z tą konkretną domeną. Każdy pretrenowany model jest opisany tutaj.
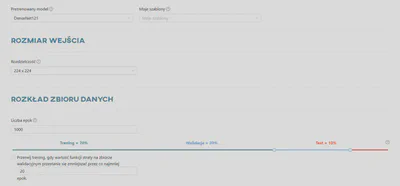
Rozmiar wejścia - odnosi się do wymiarów danych, często używanych w przypadku obrazów, których model oczekuje do przetwarzania. Większy rozmiar może prowadzić do wolniejszego szkolenia modelu.
Rozkład zbioru danych - obejmuje parametry takie jak maksymalne partie, rozmiar partii, podziały, wypalanie, liczba iteracji i liczba epok. Parametry te wspólnie określają sposób dystrybucji i przetwarzania zbioru danych podczas szkolenia, wpływając na takie czynniki, jak wydajność obliczeniowa, zbieżność modelu i ogólna wydajność szkolenia. Dostosowanie tych parametrów umożliwia precyzyjne dostrojenie procesu uczenia w celu zrównoważenia zasobów obliczeniowych i dokładności modelu.
Procentowy podział zestawu obrazów treningowych na trzy rozłączne podzbiory obejmuje wykorzystanie podzbioru treningowego do trenowania modelu, a podzbioru walidacyjnego do obliczenia jego tymczasowej dokładności. Pod koniec procesu, podzbiór testowy jest używany do zapewnienia ostatecznej dokładności modelu. Domyślny podział to 70/20/10.
Powielanie danych - stosuje różne transformacje do oryginalnych danych treningowych. W porównaniu do manipulatora zbioru danych, powielanie danych jest automatycznym procesem wbudowanym w framework, ale jego wyniki nie są widoczne dla użytkownika i zapewnia mniejszą kontrolę nad nimi niż w manipulatorze. Każde powielanie danych zostało opisane w artykule Tworzenie modelu.

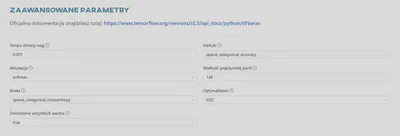
7. Zaawansowane parametry
Każdy framework oferuje różne zaawansowane parametry, takie jak tempo zmiany wag, aktywacja, wielkość pojedynczej partii, strate, optymalizator, zamrażanie wszystkich warstw, metryki i momentum.
Parametry te odgrywają kluczową rolę w dostrajaniu i optymalizacji modeli uczenia maszynowego. Wpływają na zbieżność modelu, jego zdolność adaptacyjną oraz ocenę wydajności, dlatego ich właściwa konfiguracja jest niezbędna do uzyskania optymalnych wyników.
Szczegółowy opis każdego parametru znajdziesz w artykule Tworzenie modelu.
8. Trenowanie modelu
Po wybraniu metody parametryzacji i skonfigurowaniu ustawień rozpocznij proces trenowania. Ważne jest, aby uważnie monitorować jego przebieg i w razie potrzeby wprowadzać zmiany. Szczególną uwagę zwróć na możliwość przeuczenia, czyli sytuację, w której model osiąga doskonałe wyniki na danych treningowych, ale może mieć trudności z generalizacją na nowe, nieznane dane. Przeuczenie może negatywnie wpływać na zdolność modelu do prawidłowego rozpoznawania wzorców w nowych przypadkach.
Kliknięcie ikony Zatrzymaj pozwala przerwać trenowanie na dwa sposoby:
Zatrzymaj natychmiast– natychmiast przerywa proces i usuwa całe szkolenie,Zatrzymaj z postępami– zatrzymuje proces po zakończeniu bieżącej iteracji (epoki), zachowując model i uzyskane do tej pory wyniki.
9. Odczytywanie wyników
Efektywność trenowania można ocenić po jego zatrzymaniu. Aby dowiedzieć się, jak interpretować wyniki, zapoznaj się z artykułem Śledzenie wydajności modelu.
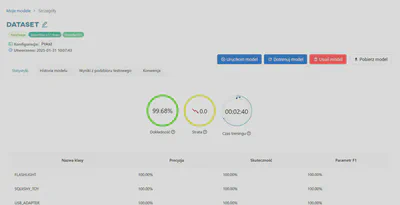
Dokładność i strata nie są jedynymi wskaźnikami, które należy brać pod uwagę, ponieważ mogą być czasami mylące. Nie determinują one jednoznacznie jakości modelu.
Podsumowanie
Budowa niezawodnego modelu AI do detekcji i klasyfikacji obiektów to złożony, ale satysfakcjonujący proces. Postępując zgodnie z tymi krokami, możesz stworzyć model spełniający Twoje wymagania dotyczące dokładności i wydajności. Pamiętaj, że rozwój modelu AI to proces iteracyjny, a jego skuteczność zależy od ciągłego doskonalenia.